








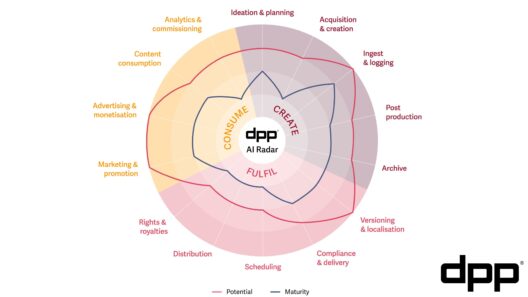













In our recent report The Future of Localisation, the DPP found that the world of localisation is benefiting from rapid developments in machine learning. In no small part this is because localisation solutions rely on foundational technologies and models which are being developed at extremely large scale for other users and industries.
2022 was the year that generative AI models reached the popular consciousness. First came image generation tools such as DALL-E and Stable Diffusion, the deep learning model popularised through the Lensa app and its magic avatars. Then came ChatGPT, the publicly accessible chat bot that enables users to converse with the GPT-3 text model.
2022 was the year that generative AI reached popular consciousness

An image generated by Midjourney using the prompt, “a software developer excitedly working on a generative AI model which creates storyboards for movies”
These technologies are a novelty today. But they are beginning to break through to the mainstream. For proof of their future ubiquity, look no further than Apple optimising their software frameworks to run Stable Diffusion on the chips built into every iPhone. The ability to generate images from text will be in billions of pockets in the coming months and years.
Meanwhile, AI giants are making huge strides. Meta is investing in direct translation from speech to speech, without intermediate steps of transcription and text translation. And NVIDIA’s Maxine can perform real time video translation. While it may not be ready for premium content just yet, it’s a glimpse of the future.
There is an arms race to build larger and better language models. Companies like Google, NVIDIA, Meta, and Open AI, are now approaching models with 1 trillion parameters. [Omniscien] And although support for less common languages has so far been a sticking point, that will change as projects like Google’s Next Thousand Languages and Meta’s No Language Left Behind gather pace.
There is an arms race to build better language models
The next generation of developments will include multi-modal models, which use many different inputs to generate an output. For example, using image recognition to understand context which is needed to create better transcription or translation of speech. This could dramatically improve translations that could otherwise be ambiguous or wrong.
Consider translating the sentence “I looked up at the crane” into Spanish. It could be translated to “Miré hacia arriba a la grúa” or “Miré hacia arriba a la grúlla”, depending on whether the subject was a piece of construction apparatus or a bird. Multi modal models could tell the difference, if accompanied by the video.
While the development of these fundamental models will underpin the future of localisation automation, we will also need tools that are specifically tuned to professional media use cases. Experts we spoke to for this research recognised their own part in building that future. One localisation service provider explained this clearly:
We need to invest in using the tools and providing the feedback. It might even take longer or cost more. But you’re building the efficiency for the future.
And a major content provider agreed:
It won't evolve unless you test it and allow it to grow and learn and develop. So it's not ready now, but we need to use it now, to see where it can go later.
We need to invest in using the tools, as we’re building the efficiency for the future




Find out more
Please contact Rowan for more information
If your company is not a DPP member, you can learn more about the benefits of membership, or contact Michelle to discuss joining.
If your company is not a DPP member, you can learn more about the benefits of membership, or contact Michelle to discuss joining.